迁移git项目
1 | git clone --mirror <原地址> # 会取得 项目名.git 的目录,里面是包含了提交历史、分支等的完整项目库 |
告知其他合作开发者修改远程库路径到新地址
1 | git remote set-url origin <新地址> |
1 | git remote -v # 可以查看当前设置的地址 |
1 | git clone --mirror <原地址> # 会取得 项目名.git 的目录,里面是包含了提交历史、分支等的完整项目库 |
告知其他合作开发者修改远程库路径到新地址
1 | git remote set-url origin <新地址> |
1 | git remote -v # 可以查看当前设置的地址 |
df.to_excel底层默认优先用的是xlsxwriter,sheet对象的类型是 xlsxwriter.worksheet.Worksheet,它没有column_dimensions属性。
可以通过在创建ExcelWriter的时候指定engine="openpyxl"让底层使用openpyxl,sheet对象的类型会变成openpyxl.worksheet.worksheet.Worksheet,它是有column_dimensions属性的。
需要安装过 openpyxl 库
1 | with pd.ExcelWriter(f"xxx.xlsx", |
周末办公楼电力系统维护停电3小时,服务器关机,电力恢复后服务器启动失败,现象是启动报错,提示让输入密码进入紧急模式。
看到主要的错误描述是:
CIFS VFS: ioctl error in smb2_get_dfs_refer rc=-5
怀疑和mount有关。
输入密码进入紧急模式,输入命令
1 | mount -a |
即根据配置文件/etc/fstab进行挂载(正常启动时也是根据此文件进行挂载)
其中/etc/fstab的内容如下
1 | ……省略若干 |
执行后看到了具体的挂载错误条目是找不到设备 /dev/sdd1
使用命令
1 | fdisk -l |
可以看到存在/dev/sdd和/dev/sdd1
1 | Disk /dev/sdd: 3.7 TiB, 4000787030016 bytes, 7814037168 sectors |
使用命令
1 | lsblk |
列出块设备信息
1 | NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT |
发现sdd下面是md126 md126p1,想起来有一块盘做成了raid0,挂载时不能按照sda、sdb、sdc的命名方式挂载,需要用/dev/md126p1,但这不是问题,因为fstab文件中确实使用了/dev/md126p1,但不应该挂载/dev/sdd1了啊,其实是这次重启之后原来的sdd1变成了现在的sdc1,可能因为上次的磁盘是热插入的,重启之后根据插入口的顺序重新分配了设备名,把fstab文件中的sdd1改成sdc1,重新mount -a成功,进入/data2查看文件,确实是之前sdd1上的。
重启会重新分配设备名导致挂载失败的问题,根据linux下磁盘sda,Linux下磁盘设备文件(sda,sdb,sdc….)变化问题_林声飘扬的博客-CSDN博客这篇博文的说法,目前没有办法直接解决,但是可以通过指定id和uuid的方式挂载而不使用sda、sdb这种名称来绕过这个问题
使用
1 | ls -la /dev/disk/by-id |
可以看到这些id和uuid就是指向sda、sdb之类的软连接,而id和uuid每次启动是固定的,那么这些软连接应该是在启动过程中生成的。
最后保险起见,我将fstab文件中的挂载设备改成了id表示
1 | # /dev/sdc1 /data2 ext4 defaults 0 0 |
SSH Tunnel解决的问题是让原本不能被访问的端口(通常是因为在不同局域网)可以被访问。
SSH Tunne按监听端口是本地还是远程分为两种命令,格式分别如下:
在本地端口(bind_address:port,指定bind_address是因为本机可能有多个网络接口,缺省在localhost上监听,只接受来自本机的链接,接受任意需指定为*)上开启监听,将收到的数据通过tunnel转发到(hostname:22),在由hostname转发到host:hostport
1 | ssh [-L [bind_address:]port:host:hostport] [user@]hostname -p 22 |
在远程端口(bind_address:port)上开启监听,将收到的数据通过tunnel转发到本机,再由本机转发到(host:hostport)
1 | ssh [-R [bind_address:]port:host:hostport] [user@]hostname -p 22 |
假设A要访问D:6379,A、D在不同局域网,最简单方法是在D所在的局域网网关上配置端口映射把D:6379映射到公网,但是很多时候出于某些因素(例如:安全考量、没有配置网关的权限、服务本身配置了只允许本地访问),不希望或无法通过把D:6379映射到公网解决,就可以考虑使用SSH Tunnel。
D所在的局域网有主机C的22端口是被映射到公网的,不妨假设映射成了X:30022,X是C和D所在局域网网关在公网的IP地址,那么可以在主机A上通过命令
1 | HostA$ ssh -L 36379:D:6379 root@X -p 30022 |
把D:6379映射成了A:36379,特别情况C和D是同一台主机,D可以写成localhost。
A所在的局域网有主机B的22端口是被映射到公网的,不妨假设映射成了X:30022,X是A和B所在局域网网关在公网的IP地址,那么可以在主机D上通过命令
1 | HostD$ ssh -g -R 36379:D:6379 root@X -p 30022 |
把D:6379映射成了B:36379,而A和B是同一局域网的,因此A可以访问到B:36379。
按理说上面的命令加了-g参数,B:36379应该被绑定在0.0.0.0:36379,但实际测试发现绑定在了127.0.0.1:36379,导致无法在A上访问,原因暂时未知(确定不是因为redis配置了保护模式),不过可以通过类似情形1的方式再把B:36379映射成A:36379,这样A就可以访问了。
1 | HostA$ ssh -L 36379:localhost:36379 root@B |
A和D所在局域网都没有主机的ssh端口被映射到公网,但我有另一台具有公网IP的主机,不妨假设为X开启着22端口,类似情形2通过命令
1 | HostD$ ssh -R 36379:D:6379 root@X |
1 | HostA$ ssh -L 46379:localhost:36379 root@X |
之后让A访问A:46379即可。
通过命令建立SSH Tunnel之后会登录到作为跳板的机器,通常我们是不需要使用这个控制台的,因此可以通过-f参数让ssh在后台运行,需要关闭tunnel时直接杀死进程。
C表示压缩数据传输
f表示后台用户验证,这个选项很有用,没有shell的不可登陆账号也能使用.
N表示不执行脚本或命令
g表示允许远程主机连接转发端口
例如情形1中的命令可以写成
1 | ssh -CfNg -L 36379:D:6379 root@X -p 30022 |
通过
1 | ps -ef|grep ssh -CfNg |
可以查看打开的tunnel。
在客户端设置/etc/ssh/ssh_config
1 | Host * |
当网络不稳定时还可以使用autossh工具来帮助自动重连。
只需要把ssh命令中的ssh换成autossh -M
例如情形1中的命令可以写成
1 | autossh -M 46379 -CfNg -L 36379:D:6379 root@X -p 30022 |
-M 后面的端口号是用来监视连接状态的,允许指定为0,这里指定为0是否可以正常监视重连以及如何监视有待研究。
另外如果autossh带了-f参数则不支持输入密码,可以配合expect脚本自动输入密码或者通过SSH密钥登录,更推荐使用密钥方式。
1 | ssh-keygen -t rsa |
会询问将密钥放在何处,默认即可。然后是输入密码,留空(否则你登录不仅需要私钥还要输入密码)。
完成后在~/.ssh目录下会生成另个文件id_rsa和id_rsa.pub,一个私钥一个公钥。
然后将公钥写入远程用户家目录下的~/.ssh/authorized_keys文件中,通过ssh-copy-id命令可以帮我们实现这一操作(相当于把公钥复制过去再追加到authorized_keys的尾部)
1 | ssh-copy-id [-p SSH端口默认22] [user@]hostname |
https://blog.csdn.net/wxqee/article/details/49234595
假设后端服务器跑在backend-server:30101,跑在本地就是localhost:30101
开发环境下通过 config/index.js 配置代理
1 | // see http://vuejs-templates.github.io/webpack for documentation. |
生产环境下通过前端所在服务器上的Nginx配置代理在
/etc/nginx/sites-enabled/default
中添加 location ^~/api/ 对应的块
1 | server { |
需求情景:
存放日志或接收并存储数据的目录,为了防止程序出错时疯狂写日志硬盘被日志或存储的数据塞满。
原理,创建一个固定大小的img文件,映射成一个目录
1 | # 创建Log.img大小1G |
参考:https://blog.csdn.net/sanve/article/details/80882731
安装
1 | apt install pptpd |
配置IP
1 | vim /etc/pptpd.conf |
查找并解开这3处的注释并修改相应配置
1 | #bcrelay eth1 |
bcrelay的意思我理解是来自虚拟局域网的广播要从哪个物理网卡转发出去
localip的意思本机是VPN服务器的IP地址
remoteip的意思是当有远程VPN客户端连接上来时被分配的IP段
我认为应该把虚拟局域网的网段和物理局域网分开,而且localip和remoteip应该在同一个网段,网上有localip和remoteip不应该在同一个网段的说法我并不认同。
配置DNS
1 | vim /etc/ppp/pptpd-options |
找到ms-dns解开注释并修改相应配置
1 | ms-dns 114.114.114.114 |
配置用户名密码
1 | vim /etc/ppp/chap-secrets |
1 | # Secrets for authentication using CHAP |
修改配置后重启PPTP服务器
1 | service pptpd restart |
打开IPv4转发
1 | vim /etc/sysctl.conf |
找到并修改或添加
1 | net.ipv4.ip_forward = 1 |
使配置生效
1 | sysctl -p service |
在网关上添加指向VPN网段的静态路由,设置下一跳地址为架设VPN服务器主机的IP,这样整个局域网都是可以通过VPN正常访问的。
如果没有操作网关的权限,也可以在需要访问的主机上添加静态路由
1 | ip route add 192.168.10.0/24 via 192.168.1.99 |
这里192.168.1.99就是架设VPN服务器的主机IP
参考:https://www.jianshu.com/p/1680c721f397 http://www.linuxfly.org/post/641/
1 | pptpsetup --create 连接名 --server VPN服务器地址 --username 用户名 --password 密码 --encrypt |
启动VPN连接
1 | pon 连接名 |
关闭VPN连接
1 | poff 连接名 |
查看路由表
1 | route -n |
添加路由,将通过VPN接入的物理局域网网段路由指定通过ppp0网口转发
1 | route add -net 192.168.1.0 netmask 255.255.255.0 dev ppp0 |
每次重连后路由会丢失,需要重新配置,可以用下面的方法在ppp0 up时自动添加路由
参考:https://blog.csdn.net/qq_27434019/article/details/102920504
1 | vim /etc/ppp/peers/连接名 |
增加ipparam一行
1 | ipparam 连接名 |
下面这步似乎不必要,不清楚作用
1 | vim /etc/network/interfaces |
增加
1 | auto tunnel |
======================================
新建脚本文件并修改权限
1 | touch /etc/ppp/ip-up.d/连接名 |
编辑脚本
1 | vim /etc/ppp/ip-up.d/连接名 |
在脚本中加入添加路由的语句
1 | route add -net 192.168.1.0 netmask 255.255.255.0 dev ppp0 |
可以poff 再 pon 再 route -n 看看路由是否自动添加
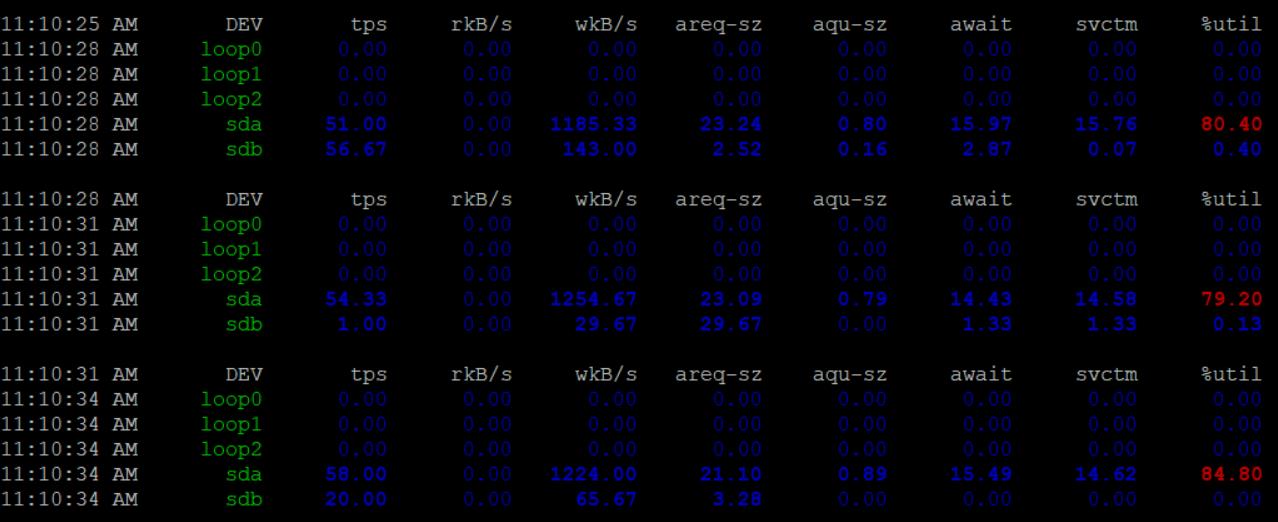
服务器其他用户反馈读取数据库很卡。
通过 sar -d -p 3 命令发现硬盘占用率比较高
通过 iotop 命令发现主要是被一个名为 [jbd2/sda2-8] 的进程占用
网上说法是 (13条消息) 性能分析之IO分析-jbd2引起的IO高_hualusiyu的专栏-CSDN博客
1 | jbd2的全称是journaling block driver 。这个进程实现的是文件系统的日志功能,磁盘使用日志功能来保证数据的完整性。这个需要评估一下安全和性能哪个更重要,解决方案是升级内核或者牺牲完整性来换性能。 |
差点被误导。
而使用命令 atop -d 发现其实是 snapd 占用
和这篇帖子情况一样 snapd持续运行,引起jbd2/sda2-8持续访问硬盘,占用大量io - Ubuntu中文论坛
1 | [#6](https://forum.ubuntu.org.cn/viewtopic.php?p=3221983#p3221983) |
snapd是ubuntu预装的一个软件包管理工具。
使用 snap list 发现只有一个core,也就是我没有基于snap安装过软件包。
通过 service snapd stop 关闭snapd,再通过 sar -d -p 3 观察硬盘占用,已经完全正常
至此确定是由snapd引发.
通过service snapd start 启动snapd,观察硬盘占用,先是再次上升数十秒后回到了正常。
如果下次再出现占用过高准备禁用或卸载snap。
禁用 systemctl disable snapd.service 卸载 apt purge snapd
相关命令
持续观察硬盘读写情况,每3秒刷新一次
1 | sar -d -p 3 |
sar常用的的参数还有监控CPU情况的
1 | sar -u 3 |
按IO从高到低排序监控进程,实时刷新
1 | iotop |
也能按IO从高到低排序,实时刷新,感觉比iotop好用
1 | atop -d |
atop也有监控CPU情况的
1 | atop -u |
在需要被挂载的服务器上安装nfs-kernel-server
1 | sudo apt install nfs-kernel-server |
通过此文件配置共享目录,样例
1 | # /etc/exports: the access control list for filesystems which may be exported |
这里配置了/data/share为共享目录,允许从192.168.1.157进行读写操作,允许从其他任意IP进行只读操作。
把共享目录的owner改成 nobody:nogroup
1 | sudo chown nobody:nogroup /data/share |
设置共享目录的权限
1 | sudo chmod 777 /data/share |
重新加载配置文件
1 | sudo exportfs -a |
在需要挂载的服务器需要安装nfs-common
1 | apt install nfs-common |
挂载命令样例 ,把140上的/data/share共享目录挂载到本地/mnt/140share
1 | mount 192.168.1.140:/data/share /mnt/140share |
使用到的端口,如果有防火墙需要设置
111/tcp+udp
2049/tcp
不同版本的NFS服务器也可能需要更多
1 | Data ONTAP: |
另外可能用到一个随机端口,在/etc/default/nfs-kernel-server中通过
1 | RPCMOUNTDOPTS="--port 33333" |
可以使之固定为33333。
更改设置后重启服务
1 | service nfs-kernel-server restart |
如果希望系统启动时自动加载文件系统
通过此文件配置系统启动时自动挂载
样例
1 | # <file system> <mount point> <type> <options> <dump> <pass> |
重新加载配置文件
1 | sudo mount -a |
配置中type是被挂载的路径的类型
常用的类型有:
nfs表示远程linux的共享路径
cifs表示远程windows的共享路径
ext4表示本地ext4路径
配置中options是挂载选项,在挂载windows目录时,通过以下方式指定用户名和密码
1 | defaults,auto,username=MZhDai,password=******,dir_mode=0777,file_mode=0777 |
另外挂载windows目录需要 mount.cifs 支持,如果没有可以通过以下命令安装
1 | sudo apt install cifs-utils |
挂载命令通过 -o指定选项
1 | sudo mount.cifs //192.168.1.107/f /mnt/107f -o user=MZhDai,pass=******,dir_mode=0777,file_mode=0777 |
还有常用的选项如
1 | ro :只读挂载 |
.cifs 可以省略,mount命令会自动识别需要挂载的路径类型
执行
1 | ls /mnt |
或
1 | df -h |
时卡住
可以使用
1 | strace ls /mnt |
或
1 | strace df -h |
查看命令执行的过程,看看最终卡在哪一步,比如卡在访问/mnt/abc
1 | cat /proc/mounts |
1 | nfsstat -s |
1 | umount <挂载点> |
如果卡住试下强制卸载
1 | umount -f <挂载点> |
或
1 | umount -lf <挂载点> |
如果还是卸载失败可以看一下哪个进程在使用挂载点下的文件
1 | lsof|grep <挂载点> |
考虑杀死进程后再卸载
1 | mount.nfs XXX XXX -o nfsvers=3 |
一般是v4版本卡住,改用v3可以解决
增加nolock挂载参数
1 | mount.nfs XXX XXX -o nfsvers=3,nolock |
主服务器:192.168.1.99
从服务器:192.168.1.150
在主服务器创建repl用户
1 | CREATE ROLE repl login replication password 'd71ea3'; |
配置repl用户访问权限
1 | vim /etc/postgresql/10/main/pg_hba.conf |
1 | host replication repl 192.168.1.150/32 md5 |
配置主服务器
1 | vim /etc/postgresql/10/main/postgresql.conf |
1 | wal_level = replica |
归档命令不加入rsync也可以,只需要在建立主从同步时手动把完整备份之后的归档复制到从库,后面配置从库时候会提到。
我实际使用的归档命令还加入了自动删除旧数据
1 | archive_command = 'DIR=/var/lib/postgresql/archivedir; test ! -f $DIR/%f && cp --preserve=timestamps %p $DIR/%f; find $DIR -type f -mtime +31|xargs rm -f' |
重启服务
1 | service postgresql restart |
停止服务
1 | service postgresql stop |
删除所有数据
1 | cd /var/lib/postgresql/10/main |
配置从服务器
1 | vim /etc/postgresql/10/main/postgresql.conf |
1 | hot_standby = on |
切换到postgres用户
1 | sudo su - postgres |
在从服务器上从主服务器创建初始备份,上面切换用户是为了不用调整文件权限
1 | pg_basebackup -h 192.168.1.99 -U repl -D /var/lib/postgresql/10/main -F p -X stream -P -R -p 5432 |
Password: d71ea3
会自动生成 recovery.conf 启动之后会读取里面的配置进行主从同步
编辑recovery.conf 在结尾追加
1 | restore_command = 'cp /var/lib/postgresql/wal_restore/%f %p' |
切回root
1 | sudo su - |
回到主服务器,如果前面主服务器归档命令没有加入rsync,那么我们现在在主服务器上 复制最近一天内修改过的归档文件到从服务器
1 | cd /var/lib/postgresql/archivedir |
相当于整体上从库建立起同步需要的数据 = 完整备份 + 归档文件 + WAL缓存
从服务器启动服务
1 | service postgresql start |
从主服务器查看从服务器同步状态
1 | select application_name, sync_state from pg_stat_replication; |