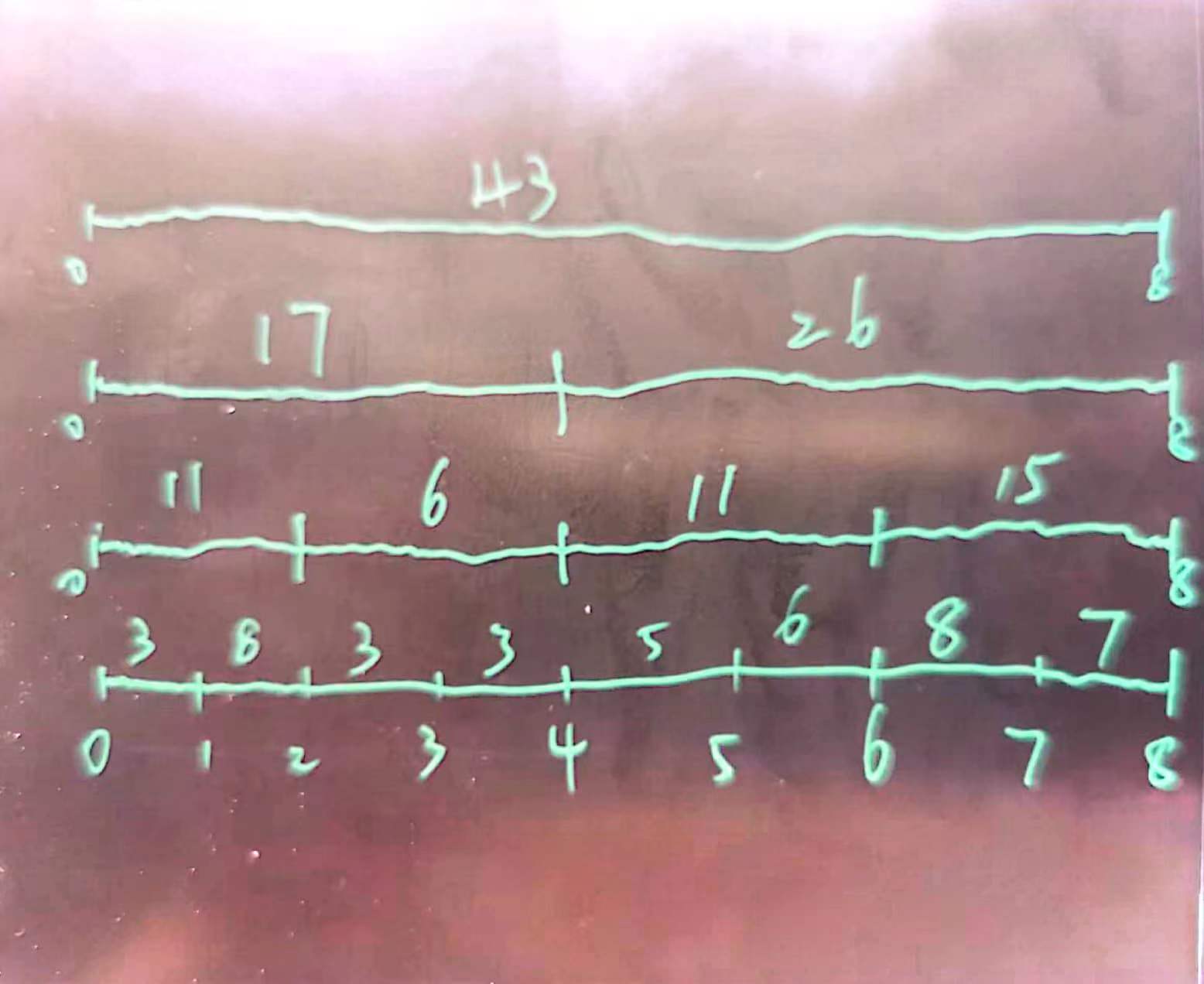
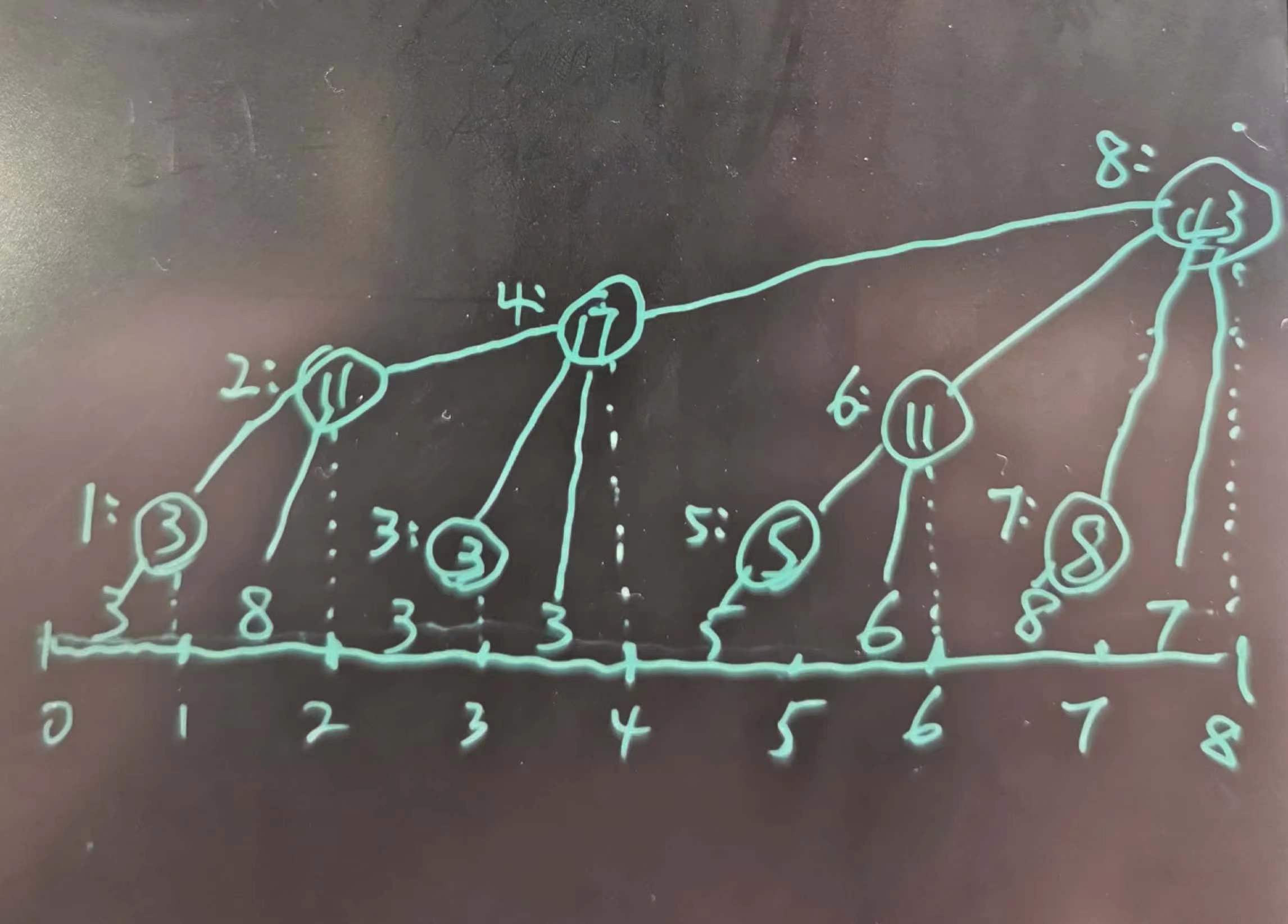
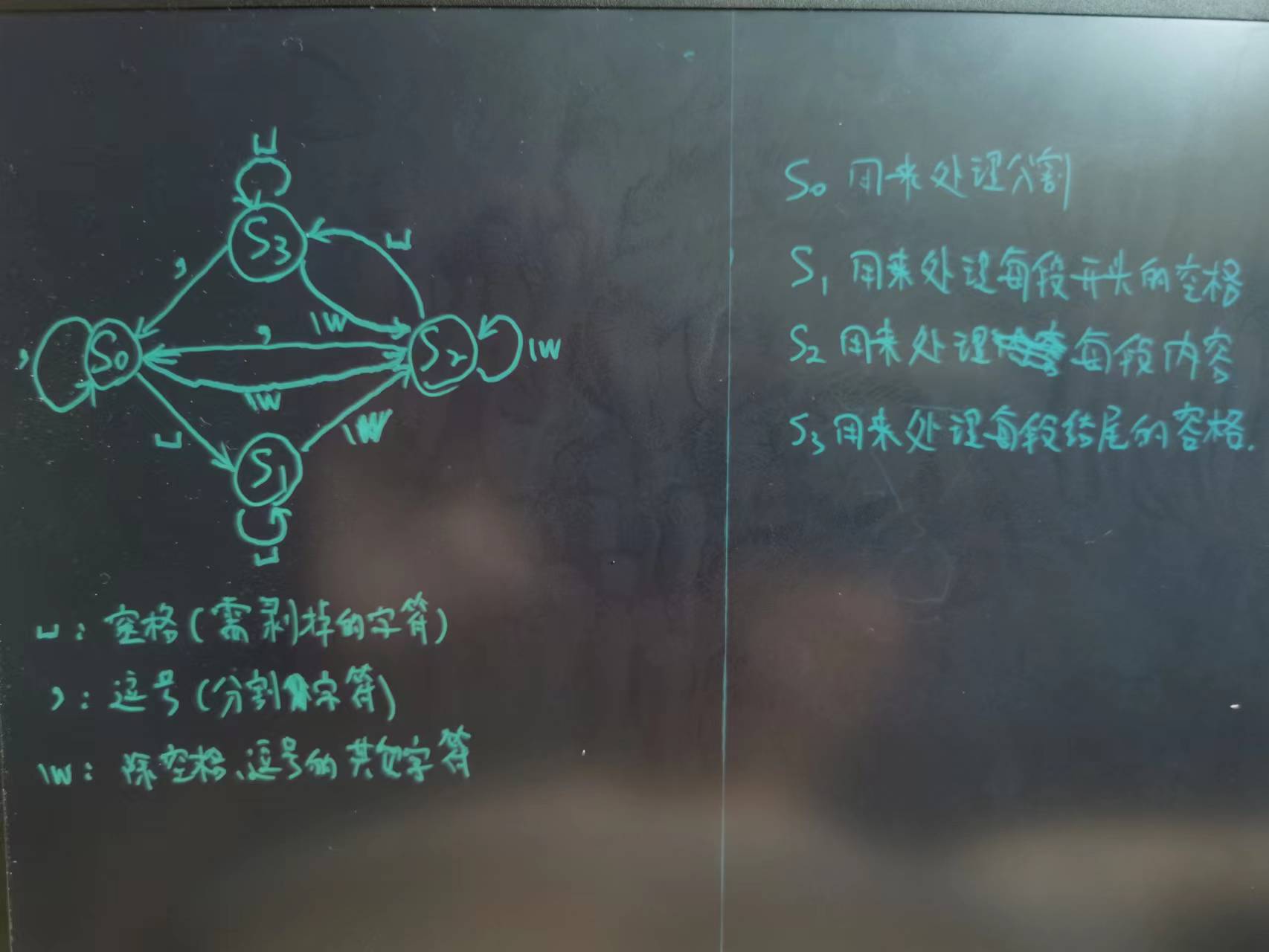
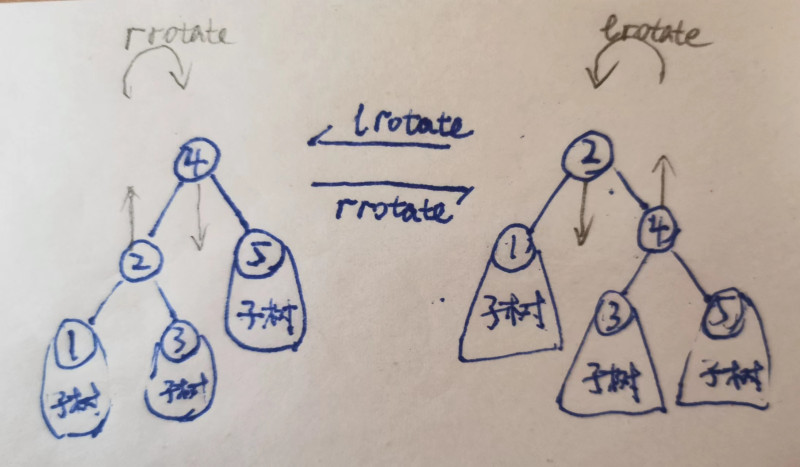
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
|
const int INF = 1e9+7;
class SegTree {
vector<int> nums;
vector<int> d;
vector<int> b;
vector<bool> v;
void build(int s, int t, int p = 1) {
if (s == t) {
d[p] = nums[s];
return;
}
int m = s + ((t - s) >> 1);
build(s, m, p * 2);
build(m + 1, t, p * 2 + 1);
d[p] = std::max(d[p * 2], d[(p * 2) + 1]);
}
void add(int l, int r, int c, int s, int t, int p) {
if (l <= s && t <= r) {
if(v[p]) {
pushdown(s, t, p);
}
d[p] += c;
b[p] += c;
v[p] = 0;
return;
}
pushdown(s, t, p);
int m = s + ((t - s) >> 1);
if (l <= m) add(l, r, c, s, m, p * 2);
if (r > m) add(l, r, c, m + 1, t, p * 2 + 1);
d[p] = std::max(d[p * 2], d[p * 2 + 1]);
}
void set(int l, int r, int c, int s, int t, int p) {
if (l <= s && t <= r) {
d[p] = c;
b[p] = c;
v[p] = 1;
return;
}
pushdown(s, t, p);
int m = s + ((t - s) >> 1);
if (l <= m) set(l, r, c, s, m, p * 2);
if (r > m) set(l, r, c, m + 1, t, p * 2 + 1);
d[p] = std::max(d[p * 2], d[p * 2 + 1]);
}
void pushdown(int s, int t, int p) {
if(v[p]) {
d[p * 2] = b[p];
d[p * 2 + 1] = b[p];
b[p * 2] = b[p * 2 + 1] = b[p];
v[p * 2] = v[p * 2 + 1] = 1;
b[p] = 0;
v[p] = 0;
} else {
if(b[p]) {
int m = s + ((t - s) >> 1);
if(v[p * 2]) {
pushdown(s, m, p * 2);
}
if(v[p * 2 + 1]) {
pushdown(m + 1, t, p * 2 + 1);
}
d[p * 2] += b[p];
d[p * 2 + 1] += b[p];
b[p * 2] += b[p];
b[p * 2 + 1] += b[p];
b[p] = 0;
}
}
}
int getmax(int l, int r, int s, int t, int p) {
if (l <= s && t <= r) return d[p];
int m = s + ((t - s) >> 1);
pushdown(s, t, p);
int max_value = -INF;
if (l <= m) max_value = std::max(max_value, getmax(l, r, s, m, p * 2));
if (r > m) max_value = std::max(max_value, getmax(l, r, m + 1, t, p * 2 + 1));
return max_value;
}
public:
SegTree(int size): nums(size) {
d.resize(size*4);
b.resize(size*4);
v.resize(size*4);
build(0, nums.size()-1, 1);
}
SegTree(const vector<int>& a): nums(a) {
d.resize(a.size()*4);
b.resize(a.size()*4);
v.resize(a.size()*4);
build(0, nums.size()-1, 1);
}
void add(int b, int e, int c) {
add(b, e-1, c, 0, nums.size()-1, 1);
}
void set(int b, int e, int c) {
set(b, e-1, c, 0, nums.size()-1, 1);
}
int max(int b, int e) {
if(e<=b) return -INF;
return getmax(b, e-1, 0, nums.size()-1, 1);
}
private:
class ItemAccessor {
public:
ItemAccessor(SegTree& st, int i): st(st), i(i) {}
ItemAccessor& operator = (int x) {st.set(i, i+1, x);return *this;}
ItemAccessor& operator += (int x) {st.add(i, i+1, x);return *this;}
ItemAccessor& operator -= (int x) {st.add(i, i+1, x);return *this;}
operator int() const {return st.max(i, i+1);}
private:
SegTree& st;
int i;
};
class RangeAccessor {
public:
RangeAccessor(SegTree& st, int b, int e):st(st), b(b), e(e) {}
void operator = (int x) {st.set(b, e, x);}
void operator += (int x) {st.add(b, e, x);}
void operator -= (int x) {st.add(b, e, x);}
private:
SegTree& st;
int b;
int e;
};
public:
ItemAccessor operator [] (int i) {
return ItemAccessor(*this, i);
}
RangeAccessor operator [] (const tuple<int, int>& range) {
return RangeAccessor(*this, std::get<0>(range), std::get<1>(range));
}
};
|