对pymongo的封装
1 | # -*- coding: utf-8 -*- |
1 | # -*- coding: utf-8 -*- |
| 字段名称 | 样例 | 获取命令(Linux) |
|---|---|---|
| 局域网IP | LIP=172.19.51.148; |
ifconfig -a |
| 网卡物理地址 | MAC=00163E066936; |
ifconfig -a |
| 硬盘序列号 | HD=TF667AY92GHRVL; |
lsblk --nodeps -no serial /dev/sda |
| PC终端设备名 | PCN=hostname; |
hostname |
| CPU序列号 | CPU=bfebfbff21040652; |
dmidecode -t 4 | grep ID |sort -u |awk -F': ' '{print $2}' |
| 硬盘分区信息 | PI=SDA^EXT4^512G; |
df -hT|grep '/$'|awk '{print $1"^"$2"^"$3}' |
| 系统盘卷标号 | VOL=0004-2CC4; |
fdisk -l|grep -e "Disk identifier" -e "Disk /dev/" |
公司对接东方证券和中泰证券的行情都是使用的盛立EFH接口,在东方证券已经部署在实盘正常使用,在中泰证券部署时发现收不到行情。
中泰证券多了个行情接入认证程序,其实怀疑是否这边有问题,但是通过
1 | tcpdump -i 网口 udp |
或明确指定组播来源
1 | tcpdump -i 网口 host 组播IP |
可以抓到组播服务器发出的数据包,说明组播到达了网口,那也说明行情接入认证是成功的。
于是深入代码调试,发现
1 | // ... |
因为m_sock被设置成了异步的,所以在没有数据时立刻返回-1,errno==EAGAIN就是正常现象。
搜索recvfrom 始终返回-1 tcpdump可以抓到包发现有人说是被防火墙拦截了。
1 | service firewalld.service stop |
执行后果然可以收到了,说明tcpdump的处理在防火墙之前,可以抓到被防火墙拦截的数据。
总忘,每次用到都要搜,记录一下
1 | from functools import cmp_to_key |
在Windows上通过net use,在linux通过mount可以把网络共享路径挂载到本地的一个盘符或一个目录,在Windows上可以直接判断路径是否存在,而在Linux挂载点总是存在的,即使挂载失败也存在一个空的文件夹,所以不能用路径是否存在来判断,可以在df命令中找挂载点。
1 | import os |
常见的背包问题根据背包的重数和最终求的值可以分为下面6类:
| 1重 | 多重 | 无穷重 | |
|---|---|---|---|
| 最大价值 | 0-1背包 | 多重背包 | 完全背包 |
| 方案数 | 0-1背包计数 | 多重背包计数 | 完全背包计数 |
以最普通的0-1背包来说,
问题描述:
有n种物品,每种1个,一个容量为C的背包,第i种物品的体积是w[i],价值是v[i],问背包能装下物品的最大价值。(也就是总体积不超过C的最大物品价值)
思路:
用dp[i][c]表示前i个物品在容量为c的背包时能装下的最大价值,每个物品都可以取或者不取,在面对第i个物品时,如果取那么
1 | dp[i][c] = dp[i-1][c-w[i]]+v[i] if c>=w[i] |
如果不取那么
1 | dp[i][c] = dp[i-1][c] |
并且dp[i][c]对于c应该是单调不减的,因为容量变大总价值不可能减少。
所以有
1 | dp[i][c] >= dp[i][c-1] |
综上,我们有
1 | dp[i][c] = max(dp[i-1][c], dp[i][c-1]); |
有时候要求背包必须是满的,则没有上述单调性,或者我们总是不考虑单调性,而在给出最终答案前去遍历dp[n-1]得到最大值,鉴于此我们把上式简化,并加上循环
1 | for(int i=0;i<n;i++) { |
注意到dp[i][c] = dp[i-1][c]相当于对于每个新的物品我们总是在前一物品算好的dp数组上做修改,那么能不能把第一维去掉直接修改呢,问题就在于dp[i-1][c-w[i]]我们会用到c-w[i]位置,而它可能在第i趟循环时修改了,如果我们再利用这个状态相当于物品i被用了两次,所以我们需要第i-1趟循环时的值,考虑到只会引用到c更小是位置,我们可以把内层循环反向,这样就不会在第i趟循环时修改到c-w[i]位置的值了。
1 | for(int i=0;i<n;i++) { |
循环完成后 max(dp)就是背包能取得的最大价值。
0-1背包算法时间复杂度O(n*C),空间复杂度O(C)。
问题描述:
有n种物品,每种m[i]个,一个容量为C的背包,第i种物品的体积是w[i],价值是v[i],问背包能装下物品的最大价值。
思路:
如果把m[i]个相同的物品视作m[i]种物品则问题可以规约为0-1背包,时间复杂度O(∑m[i]*C),那么能不能利用m[i]个物品是相同的特性来优化时间复杂度呢?是可以的,对于第i种物品,我们不把它视作m[i]个相同的物品,而是把他们按二进制的方式组合,分成1个物品组合,2个物品组合,4个物品组合,……,这样m[i]个物品就被组合成了log(m[i])个物品,再规约为0-1背包,显然不影响最终解。算法时间复杂度O(∑log(m[i])*C),组合成的新物品可以边循环边生成因此没有空间开销,空间复杂度还是O(C)。
问题描述:
有n种物品,每种无穷个,一个容量为C的背包,第i种物品的体积是w[i],价值是v[i],问背包能装下物品的最大价值。
思路:
虽然每种物品个数是无穷的,但背包实际的容量的有限的,对于第i种物品最多装下C/v[i]个,我们可以令m[i]=C/v[i]即可把问题规约为多重背包问题。而实际上还有更简单的解法,我们在思考0-1背包空间降维时遇到的问题,“问题就在于dp[i-1][c-w[i]]我们会用到c-w[i]位置,而它可能在第i趟循环时修改了,如果我们再利用这个状态相当于物品i被用了两次”,而这对于完全背包问题来说正是我们需要的,因此只有把0-1背包内层循环的顺序改成正向的就实现了完全背包。
1 | for(int i=0;i<n;i++) { |
循环完成后 max(dp)就是背包能取得的最大价值。
完全背包的复杂度和0-1背包相同,算法时间复杂度O(n*C),空间复杂度O(C)。
问题描述:
有n种物品,每种1个,一个容量为C的背包,第i种物品的体积是w[i],问恰好装满背包的方案数。
思路:
对于计数问题通常会忽略价值,或者认为价值等于体积,用dp[i][c]表示前i个物品在容量为c的背包时恰好装满的方案数,则有
1 | dp[i][c] = dp[i-1][c] + (dp[i-1][c-w[i]] if c>=w[i] else 0) |
即要么不用第i个物品,要么用第i个物品。
同样我们可以用0-1背包类似的思想把空间降成1维,内层循环用倒序。
1 | dp[0] = 1; |
对于多重背包,要明确一点,相同种类的背包视为相同背包(例如5个第i种背包,取3个只会形成1种方案,而不是5C3种方案),那么还是可以按二进制的方式组合。
问题描述:
有n种物品,每种无穷个,一个容量为C的背包,第i种物品的体积是w[i],问恰好装满背包的方案数。
思路:
和完全背包类似思路,直接上代码:
1 | dp[0] = 1; |
1 | import math |
我们知道在Linux上的任务计划可以通过cron服务管理,cron服务设置任务运行时间有着自定义的时间表达式,形如
1 | # m h dom mon dow command |
这条记录表示在每周一到周五的08:58自动运行/root/run.sh脚本,除去command,我们看到时间表达式有m, h, dom, mon, dow几个部分,分别表示分钟、小时、每月几号、月份、星期几。几号和星期几通常是二选一,指定了一个另一个就会指定成*表示任意,也可以都指定成*,则表示每天。
dow的1-5表示周一到周五,也可以用逗号分割列举具体星期几,例如1,3,5表示每周一三五,除了周几,其他时间项也都可以使用此表示法。
除了用-表示范围,还可以用/表示频率例如:
1 | # m h dom mon dow command |
表示每周一~周五,小时为9点到14点,从0分开始每5分钟运行一次脚本,这样每天第一次运行的时间是09:00,每天最后一次运行的时间是14:55,中间都是每隔5分钟运行一次。
一些程序允许使用扩展的CRON时间表达式,一般会增加秒的表示
可能通过第一位也可能通过最后一位表示。
即
1 | s m h dom mon dow |
或
1 | m h dom mon dow s |
具体要阅读文档来查询。
还有一种扩展是增加随机性指定,通过以字母H开头表示
例如
1 | H(55-59) 8 * * 1-5 /root/run.sh |
表示周一到周五,每天[08:55, 09:00)之间的一个随机时间运行/root/run.sh,这样通常是为了缓解多个任务同时启动的压力。
1 | from croniter import croniter |
有时候我们即需要上次触发时间,又需要下次触发时间,要么我们理解了迭代器的方式通过取prev再取next的next,要么我们创建两个cron对象分别取prev和next。
croniter允许通过datetime对象或者timestamp(即time.time()的返回值,float类型)来使用cron对象,但是我们的时间表达式是带有时区概念的,所以cron对象必须明确知道我们的时区,否则将不能正确工作,一种方式是我们使用datetime初始化cron对象,取next或prev的时候也使用datetime类型接收,这时候即使时区不明确也不要紧,但是不能使用timestamp接收next和prev的返回值,否则cron对象会默认使用UTC时区导致返回的float值不正确,如果我们使用带时区的datetime来初始化cron对象则没有这个问题,上面例子就是通过带时区的方式初始化的。
另外,python的cron对象是同时支持秒扩展和随机扩展的,秒放在最后一位,使用随机需要在初始化时指定hash_id,不同的hash_id将影响随机结果,例如我还是上面的例子,但是我需要触发时间不在分钟的整点,而在这一分钟内随机的秒数上,就可以写成下面这样
1 | cron = croniter('0/5 9-14 * * 1-5 H(0-59)', now, hash_id="hash_id") |
1 | # 安装nvm |
1 | 安装项目依赖 |
视需求情况安装
1 | apt install nodejs-dev node-gyp libssl1.0-dev |
其中pm2可以直接启动js作为服务器运行
1 | 启动项目 |
其中app.js为服务器启动脚本,参考脚本如下:
1 | // app.js |
LVM是 Logical Volume Manager(逻辑卷管理)的简写,它是Linux环境下对磁盘分区进行管理的一种机制,可以将多个物理硬盘进行重新组织,划分成多个逻辑卷并可以动态改变卷大小(例如增加新的硬盘来扩展已有的逻辑卷)
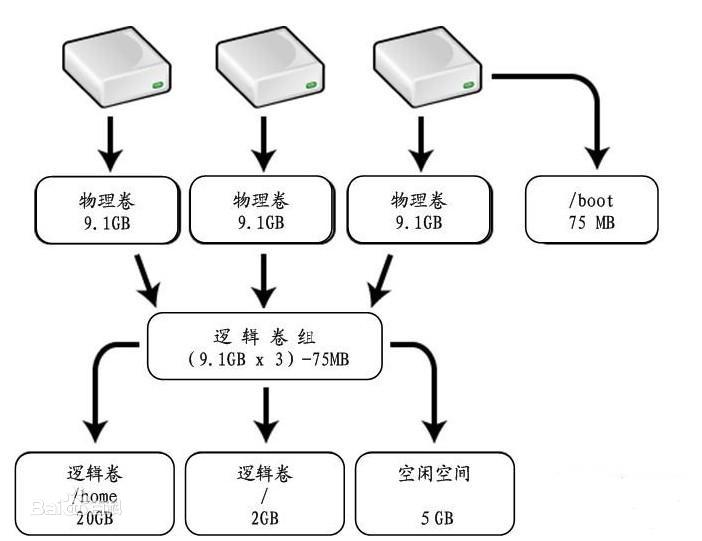
| 功能 | PV管理 | VG管理 | LV管理 |
|---|---|---|---|
| scan 扫描 | pvscan | vgscan | lvscan |
| create 创建 | pvcreate | vgcreate | lvcreate |
| display 显示 | pvdisplay | vgdisplay | lvdisplay |
| remove 移除 | pvremove | vgremove | lvremove |
| extend 扩展(增加) | vgextend | lvextend | |
| reduce 减少 | vgreduce | lvreduce |
PV对应物理卷
例如 PV1 <=> /dev/sda1
VG是卷组,由PV构成的集合,也是由LV构成的集合
在PV上可以划分LV,即逻辑卷
1 | pvcreate <后面可以是/dev/sdb这样的未分区整个盘也可以是/dev/sdb1这样的一个分区> |
例如:pvcreate /dev/sda
1 | vgcreate 卷组名 物理卷 |
例如:vgcreate vg_abc /dev/sda
向卷组中增加物理卷
1 | vgextend vg_abc /dev/sdb |
从卷组vg_abc创建一个大小为1G的逻辑卷lv_data
1 | lvcreate -L 1G vg_abc -n lv_data |
从卷组vg_abc创建一个占卷组大小100%的逻辑卷lv_data
1 | lvcreate -l 100%VG vg_abc -n lv_data |
1 | mke2fs -t ext4 -L "the ext4 on lvm" /dev/vg_abc/lv_data |
删除LV将空间还给VG
1 | lvremove /dev/vg_abc/lv_data |
在/etc/fstab中添加内容:
1 | /dev/vg_abc/lv_data /data ext4 defaults 0 0 |
如果使用新购置硬盘,按照前面的方式 创建物理卷 并 扩展卷组,然后再扩展逻辑卷
1 | lvextend -L +10G /dev/mapper/vg_abc-lv_data |
1 | lvextend -l +40%FREE /dev/mapper/vg_abc-lv_data |
1 | lvextend -l +40%VG /dev/mapper/vg_abc-lv_data |
1 | resize2fs /dev/mapper/vg_abc-lv_data |