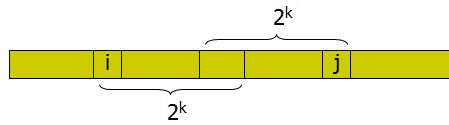
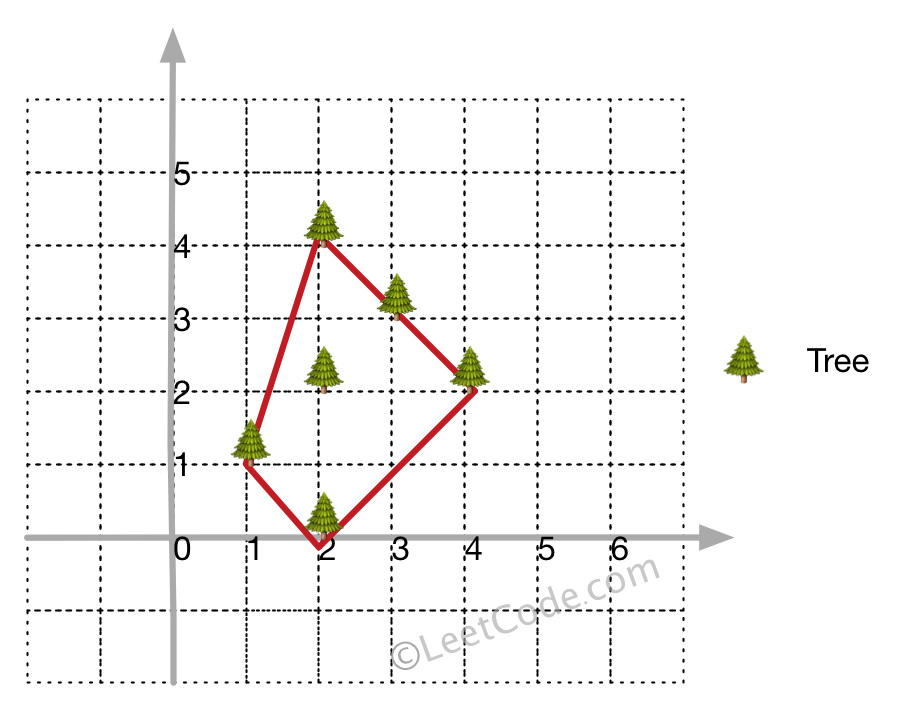
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
| typedef long long ll;
template<typename T>
class ChthollyTree {
private:
struct ChthollyNode {
ll l, r;
mutable T w;
ChthollyNode(ll l, ll r=0, const T& w=T()): l(l),r(r),w(w) {}
bool operator < (const ChthollyNode& n) const {
return l < n.l;
}
};
set<ChthollyNode> s;
public:
ChthollyTree(ll n=1e9+2, const T& v=T()) { s.insert(ChthollyNode(-1, n, v)); }
auto split(ll pos) {
auto itr = s.lower_bound(pos);
if (itr != s.end() && itr->l == pos) return itr;
--itr;
auto l = itr->l;
auto r = itr->r;
auto w = itr->w;
s.erase(itr);
s.insert(ChthollyNode(l, pos, w));
return s.insert(ChthollyNode(pos, r, w)).first;
}
void update(ll l, ll r, function<void(ChthollyNode&)> f) {
auto right = split(r), left = split(l);
for(auto itr = left; itr != right; itr++) {
f(const_cast<ChthollyNode&>(*itr));
}
}
void assign(ll l, ll r, const T& w) {
auto right = split(r), left = split(l);
s.erase(left, right);
s.insert(ChthollyNode(l, r, w));
}
void visit(ll l, ll r, function<void(const ChthollyNode&)> f) {
auto left = s.lower_bound(l);
if (left == s.end() || left->l != l) --left;
auto right = s.lower_bound(r);
for(auto itr = left; itr != right; itr++) {
f(*itr);
}
}
private:
class ItemAccessor {
public:
ItemAccessor(ChthollyTree& ct, ll i): ct(ct), i(i) {}
ItemAccessor& operator = (const T& x) {ct.assign(i, i+1, x);return *this;}
ItemAccessor& operator += (const T& x) {ct.update(i, i+1, [x](auto& p){p.w += x;});return *this;}
ItemAccessor& operator -= (const T& x) {ct.update(i, i+1, [x](auto& p){p.w -= x;});return *this;}
operator T() const {T r;ct.visit(i, i+1, [&r](auto& p){r = p.w;}); return r;}
private:
ChthollyTree& ct;
ll i;
};
class RangeAccessor {
public:
RangeAccessor(ChthollyTree& ct, ll b, ll e):ct(ct), b(b), e(e) {}
void operator = (const T& x) {ct.assign(b, e, x);}
void operator += (const T& x) {ct.update(b, e, [&x](auto& p){p.w += x;});}
void operator -= (const T& x) {ct.update(b, e, [&x](auto& p){p.w -= x;});}
private:
ChthollyTree& ct;
ll b;
ll e;
};
public:
ItemAccessor operator [] (ll i) {
return ItemAccessor(*this, i);
}
RangeAccessor operator [] (const tuple<ll, ll>& range) {
return RangeAccessor(*this, std::get<0>(range), std::get<1>(range));
}
T sum(ll l, ll r) {
T ret = 0;
visit(l, r, [&](auto& p) {
ret += p.w * (std::min(p.r, r)-std::max(p.l, l));
});
return ret;
}
T min(ll l, ll r) {
bool first = true;
T ret = 0;
visit(l, r, [&](auto& p) {
if(first) {
first = false;
ret = p.w;
} else {
ret = std::min(ret, p.w);
}
});
return ret;
}
T max(ll l, ll r) {
bool first = true;
T ret = 0;
visit(l, r, [&](auto& p) {
if(first) {
first = false;
ret = p.w;
} else {
ret = std::max(ret, p.w);
}
});
return ret;
}
};
|